
TeknoCerdas.com – Salam cerdas untuk kita semua. Salah satu konsep data modeling yang ada pada DyanamoDB adalah single-table design. Konsep yang mungkin terdengar aneh bagi yang datang dari background SQL database tradisional. Untuk memudahkan ilustrasi maka saya gunakan contoh sebuah blog database.
Artikel bagian pertama dapat dibaca pada link berikut:
DynamoDB Single-Table Design: Membuat Blog (1)
Tanggalkan konsep tentang normalisasi database, karena pada NoSQL database duplikasi data adalah hal yang wajar dan tidak perlu ditakutkan. Namun usahakan seminimal mungkin terjadi duplikasi data. Karena semakin sedikit duplikasi maka kompleksitas untuk menjaga konsistensi data juga menurun.
Jadi jika dipersingkat DynamoDB lebih dikhususkan untuk melakukan operasi OLTP dengan performa tinggi dan bukan didesain untuk OLAP. Artikel ini akan menitikberatkan pada pembahasan contoh single-table design yaitu sebuah blog.
Daftar Isi
Contoh Database Blog
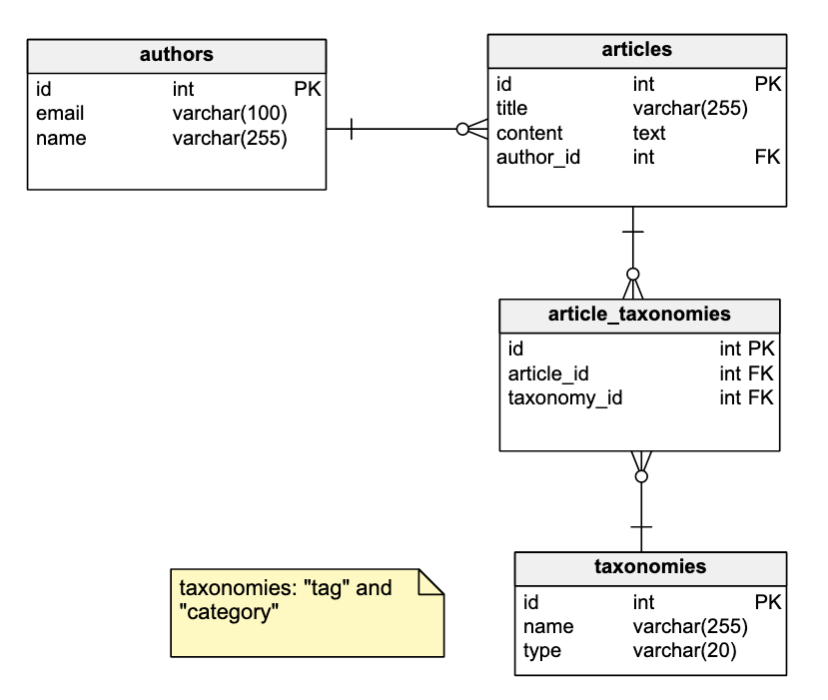
Dibawah ini adalah contoh sebuah blog database yang sederhana. Jika dimodelkan dalam RDMBS maka terdiri dari empat tabel yaitu: author, articles, taxonomies dan article_taxonomies.
Pentingnya Access-Pattern
Pada konsep single-table design mengetahui access-pattern dari aplikasi yang dibuat adalah kunci nomor satu. Jadi jika aplikasi yang dibuat adalah sebuah blog maka tentukan access-pattern apa saja yang mungkin dilakukan pada sebuah blog.
Jadi nantinya hanya ada satu tabel bernama “blogs”. Tidak ada tabel lain, semua access pattern akan mengarah ke tabel tersebut dengan tambahan Global Secondary Index (GSI) jika diperlukan.
Filtering data pada sisi aplikasi harus dihindari sebisa mungkin agar kode tidak menjadi kompleks dalam memproses data. Data sudah harus siap digunakan dari DynamoDB.
Untuk menjaga performa agar tetap konsisten operasi Scan harus dihindari karena akan membaca seluruh item pada tabel sehingga ini tidak scalable. Operasi filter pada Query sebisa mungkin juga hindari ketika dataset sangat besar. Hal ini akan mempengerahui performa dan biaya.
Alternatif tanpa menggunakan filter adalah memasukkan beberapa data pada atribut yang sama sehingga menjadi composite key. Atribut yang umum digunakan untuk composite key adalah sort key. Pada bagian berikutnya akan dicontohkan data model yang menggunakan composite key.
Contoh Access-Pattern Blog
Setelah menentukan access-pattern maka gunakan tiga generic atribut untuk menyusun single-table yang dibuat yaitu pk untuk partition key, sk untuk sort key dan data untuk GSI sort key.
Simulasikan access-pattern dengan data kecil untuk mempermudah proses desain tabel. Sebelum melakukan data modeling tulis semua access-pattern yang mungkin digunakan oleh aplikasi dalam hal ini blog.
Ini adalah contoh access-pattern yang saya gunakan.
- Get article by ID
- Get articles by date, month or year
- Get most viewed articles monthly
- Get most commented article
- Get articles by status
- Get articles by tag
- Get articles by category
- Get articles by author
- Get comment by ID
- Get comments by article ID
- Get category by ID
- Get categories with number of articles
- Get tag by ID
- Get tags with number of articles
Untuk mendukung akses pattern diatas, saya juga memerlukan sebuah GSI dengan atribut sk sebagai partition key dan atribut data sebagai sort key. Dari access-pattern yang telah ditentukan, data modelnya dapat dicontohkan seperti dibawah.
| Primary Key | Attributes | ||||
| pk | sk | data | title | name | |
| author#ID-1 | author | active#0000002 | John Doe | johndoe@example.com | |
| comment#ID-1 | comment#article#ID-1 | published#2022-03-12 | John Smith | johnsmith@example.com | |
| category#ID-1 | category | active#0000001 | Java | ||
| category#ID-2 | category | active#0000001 | PHP | ||
| category#ID-3 | category | active#0000002 | Programming | ||
| tag#featured | tag | active#0000001 | featured | ||
| tag#security | tag | active#0000001 | security | ||
| article#ID-1 | article | source#published#2022-03-10 | Java Programming | ||
| article#ID-2 | article | source#published#2022-03-10 | PHP Programming | ||
| article#ID-1 | article#author#ID-1 | copy#published#2022-03-10 | Java Programming | ||
| article#ID -2 | article#author#ID-1 | copy#published#2022-03-10 | PHP Programming | ||
| article#ID -1 | article#category#ID-3 | copy#published#2022-03-10 | Java Programming | ||
| article#ID -1 | article#category#ID-1 | copy#published#2022-03-10 | Java Programming | ||
| article#ID -2 | article#category#ID-3 | copy#published#2022-03-10 | PHP Programming | ||
| article#ID -2 | article#category#ID-2 | copy#published#2022-03-10 | PHP Programming | ||
| article#ID -1 | article#tag#featured | copy#published#2022-03-10 | Java Programming | ||
| article#ID -1 | article#tag#security | copy#published#2022-03-10 | Java Programming | ||
| article#ID -1 | no_views#2022-03 | 0000001200 | Java Programming | ||
| article#ID -2 | no_views#2022-03 | 0000000820 | PHP Programming | ||
| article#ID -1 | no_comments#2022-03 | 00002 | Java Programming | ||
| article#ID -2 | no_comments#2022-03 | 00000 | PHP Programming | ||
| Primary Key | Projected Attributes | ||
| pk | sk (GSI PK) | data (GSI SK) | title, summary, meta, categories, author |
Saya menambahkan sebuah Global Secondary Index (GSI) dengan atribut sk sebagai partition key dan data sebagai sort key. Dengan menggunakan data model diatas maka saya dapat memenuhi access-pattern yang telah ditentukan sebelumnya.
| Access Pattern | Tabel/GSI | DynamoDB Query |
| Get article by ID | blogs | pk="article#ID-1" |
| Get articles by date, month or year | data_index | sk="article" and data.startWith("source#published#2022-03") |
| Get most viewed articles monthly | data_index | sk="no_views#2022-03" |
| Get most commented article | data_index | sk="no_comments#2022-03" |
| Get articles by status | data_index | sk="article# and data.startWith("copy#published#") |
| Get articles by category | data_index | sk="article#category#ID-1 " and data.startWith("copy#published#") |
| Get articles by author | data_index | sk="article#author#ID-1 " and data.startWith("copy#published#") |
| Get comment by ID | blogs | pk="comment#ID-1" |
| Get comments by article ID | data_index | sk="comment#article#ID-1" and data.startWith("published#") |
| Get category by ID | blogs | pk="category#ID-1" |
| Get categories with number of articles | data_index | sk="category" and data.startWith("published#") |
| Get tag by ID | blogs | pk="tag#featured" |
| Get tags with number of articles | data_index | sk="tag" and data.startWith(active#") |
Query pada tabel blogs sebagian besar digunakan untuk mendapatkan sebuah single item dari tabel. Sedangkan GSI data_index digunakan untuk sebagian besar query yang mengembalikan lebih dari satu item. Karena pada DynamoDB tidak mengenal join maka strategi yang saya lakukan adalah melakukan duplikasi data pada relasi many-to-many seperti article-category dan article-tag.
Saya juga menggunakan composite key dimana saya menumpuk beberapa nilai pada sebuah sort key. Sebagai contoh source#published#2022-03-10 dengan composite key seperti itu saya dapat melakukan filter status dan tanggal menggunakan operator start-with tanpa perlu menggunakan filter.
DynamoDB akan dengan efisien akan menemukan lokasi partisi dari data dengan cepat dan menghemat biaya karena semakin sedikit data yang dibaca.
Data model yang saya gunakan lebih dioptimalkan untuk access-pattern baca. Sehingga pada beberapa kondisi data harus diduplikasi untuk setiap perubahan yang terjadi. Ini adalah salah satu kekurangan yang harus diterima.
Untuk menjaga konsistensi data karena adanya duplikasi maka saya menggunakan DyanmoDB Stream. Dimana setiap ada item baru, perubahan item atau item dihapus maka informasi perubahan tersebut akan dikirim ke fungsi Lambda yang telah disiapkan. Fungsi ini akan melakukan aksi yang diperlukan diperlukan seperti melakukan duplikasi data atau menghapus data yang tidak diperlukan.
Berikut adalah pseudocode untuk fungsi Lambda ketika ada article baru dibuat:
if eventName == 'INSERT' and record.type == 'article'
createNewArticleItem -> pk = record.pk, sk = 'article#author#{record.pk}, ...
foreach record.categories as item
createNewArticleItem -> pk = record.pk, sk = 'article#category#{item.pk}, ...
foreach record.tags as item
createNewArticleItem -> pk = record.pk, sk = 'article#tag#{item.pk}, ...
endifKesimpulan
Untuk menyimpan data secara efisien pada DynamoDB maka yang diperlukan:
- Kesampingkan pengetahuan anda tentang RDMBS seperti normalisasi
- Tentukan access-pattern dari aplikasi yang dibuat sebelum mendesain data model
- Melakukan duplikasi bukanlah pelanggaran di NoSQL. Untuk menjaga konsistensi dapat dilakukan pada sisi aplikasi dengan memanfaatkan DynamoDB Stream.
- Hindari penggunaan operasi Scan pada tabel besar karena akan membaca setiap item ditabel sehingga tidak scalable dan akan menggunan RCU lebih banyak.
- Hindari penggunaan filter expression pada operasi query pada dataset yang besar. Sebisa mungkin gunakan composite key daripada filter.
- Jangan membuat GSI jika memang tidak diperlukan oleh access-pattern.
- Gunakan composite key yaitu menumpuk beberapa nilai sekaligus pada sebuah atribut yang akan digunakan sebagai sort key. Sehingga tidak perlu menggunakan operasi filter.
Berikut adalah beberapa referensi yang bagus untuk mempelajari single-table design DynamoDB: